
The algorithmic strategy business likes quoting academic research to support specific trading factors, particularly in the equity space. Unfortunately, the rules of conventional academic success provide strong incentives for data mining and presenting ‘significant’ results. This greases the wheels of a trial-and-error machinery that discover factors merely by the force of large numbers and clever fitting of the data: some 400 trading factors have so far been published in academic journals (called the “factor zoo”). The number of unpublished and rejected tested factors is probably a high multiple of that. With so many tryouts, conventional significance indicators are largely meaningless and misleading. As with the problem of overfitting (view post here), the best remedies are plausible mathematical adjustments and reliance upon solid prior theory.
Harvey, Campbell and Yan Liu (2019), “A Census of the Factor Zoo”.
The post ties in with SRSV’s summary lecture on macro information inefficiency.
The below are quotes from the paper. Emphasis and cursive text have been added.
Factor zoo and moral hazard
“The rate of factor production in the academic research is out of control. We document over 400 factors published in top journals. Surely, many of them are false.”
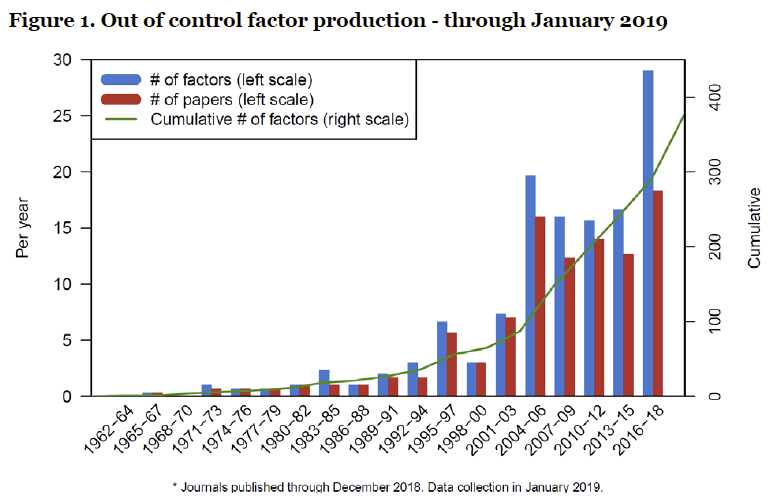
The link to the Google sheet1 with the Factor Census is https://tinyurl.com/y23ozzkc
“Academic journals overwhelmingly publish papers with positive results that support the hypothesis being tested. Papers with positive results tend to be cited more than papers with negative results. Journal quality is often proxied by impact factors, which measure the number of citations the papers published by the journal get. Journal editors want higher impact factors. Authors figure this out. To maximize the chance a paper is published, the paper needs a positive result. Hence, the data mining begins.”
“The backtested results published in academic outlets are routinely cited to support commercial products. As a consequence, investors develop exaggerated expectations based on inflated backtested results and are then disappointed by the live trading experience.”
Why (most) significant statistics are not significant
“Almost all of the past research fails to take into account the multiple testing problem: with so many factors tried, some will appear ‘significant’ purely by chance.”
“We must take multiple testing into account when assessing statistical significance. We usually focus on an acceptable rate of false positives (e.g., a 5% level) and will often declare a factor significant at the 5% level (e.g., two standard errors from zero, aka two sigma). This works for a single try, but if we test for instance, 20 different factors, one will likely be two sigma—purely by chance. If we accept this factor as a true factor, the error rate will not be 5%, but closer to 60%. Hence, it is crucial to impose a higher hurdle for declaring a factor significant. Two sigma is far too weak a threshold and leads to an unacceptably large number of false positives.”
“Whereas we can count the factors published in academic journals, we cannot count the factors that do not make it into journals….the ‘file drawer effect’… The ‘file drawer effect’ means that we are not aware of all the factors that have been tested…This is evident from the severe truncation of the distribution of t-statistics presented [in academic papers, which incredibly seems to suggest that trading factors rarely lack statistical significance].”
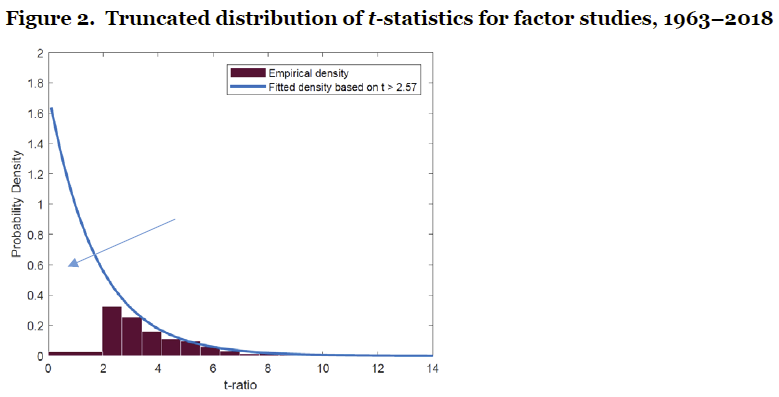
“A researcher invests time in a project and realizes the factor will not exceed the usual significance level…The researcher is faced with the following dilemma. Should she expend the effort to finish the project and invest her time in the peer review process at potentially multiple journals, or walk away from the project…put it in the file drawer?…So aside from the decreased probability of publishing a paper with negative results, researchers often file away papers they are not excited about.”
“Many multiple testing corrections are suggested in the literature. The simplest is the Bonferroni correction. Suppose we try 50 factors and find that one is approximately three sigma with a p-value of 0.01. Three sigma is impressive under a single test (usually we look for a p-value < 0.05)—but we did 50 tests. The Bonferroni correction simply multiplies the p-value by the number of tests. So the Bonferroni-adjusted p-value is 0.50, which is much larger than our usual 0.05.”
The importance of plausible prior theory
“Suppose Researcher A develops an economic model from first principles. An implication of the model is that a particular formulation of a factor should impact the cross-section of expected returns. Such a formation has not been tested before. Researcher A goes to the data and tests this particular factor formation and finds that it is ‘significant.’ Researcher B has a much different strategy. This researcher uses no theory or economic foundation. Researcher B is trained in data science rather than in economics. He tests various combinations and permutations of CRSP and Computstat data and ‘discovers’ a new factor. Should we treat the discovery from Researcher A (first principles) and Researcher B (data mined) identically? We think not…Injecting some prior beliefs into the decision making is critically necessary.”